Proxmox VE: 2 노드 HA 기능 테스트(Part 3 장애 테스트)
HA를 구성하는 절차입니다. 모든 HA 구성 파일은 /etc/pve/ha/ 디렉토리에 있고, 클러스터 노드에 자동으로 배포되고 모든 노드가 동일한 HA 구성을 공유합니다.
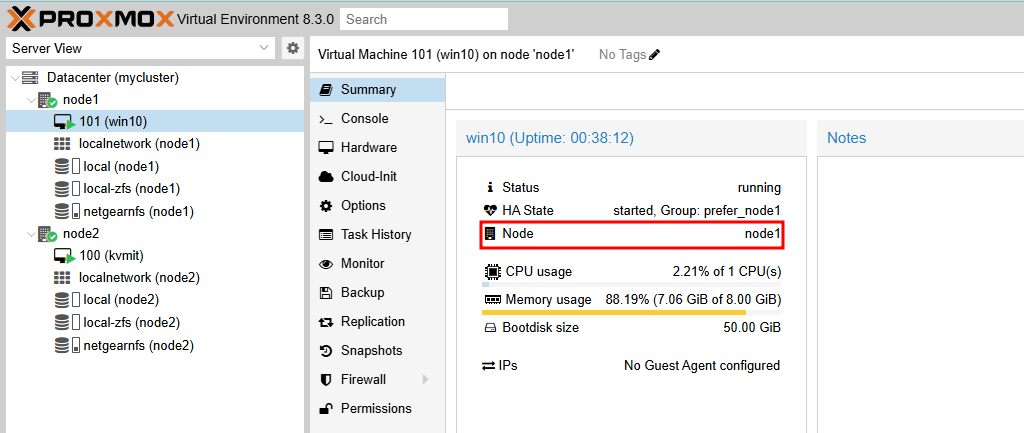
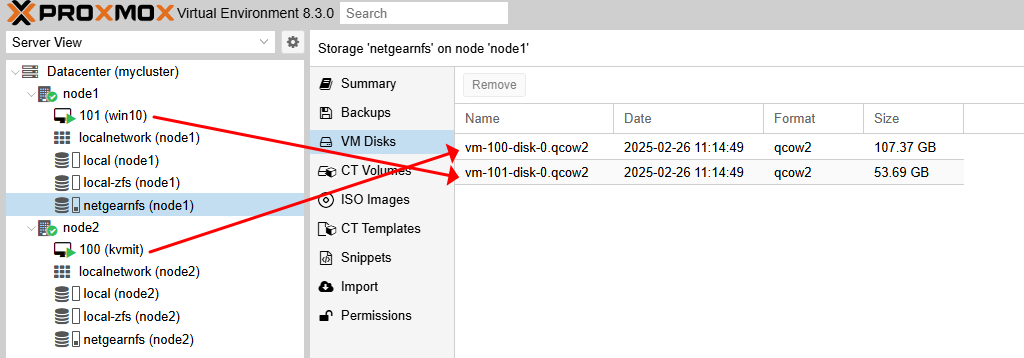
- node1과 node2에서 NFS 저장소(netgearnfs)를 공유하고 있으며, vm:100(kvmit)는 node2에서, vm:101(win10)은 node1에서 실행되고 있는 환경입니다.
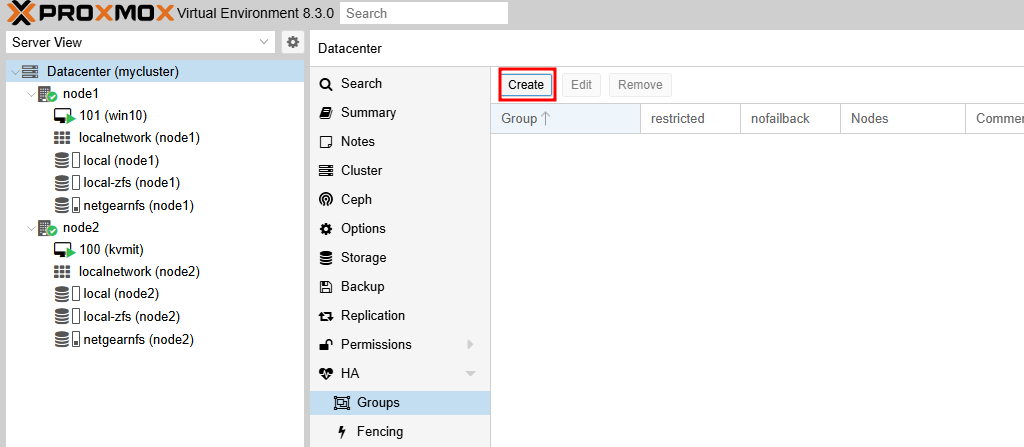
- HA Group을 생성합니다. HA Group는 클러스터 노드 그룹을 정의하는 데 사용되며, 리소스는 해당 그룹의 멤버(node)에서만 실행되도록 제한할 수 있습니다. HA Group 구성은
/etc/pve/ha/groups.cfg에 저장됩니다.Datacenter > HA > Groups메뉴를 선택하고Create 버튼을 클릭합니다.
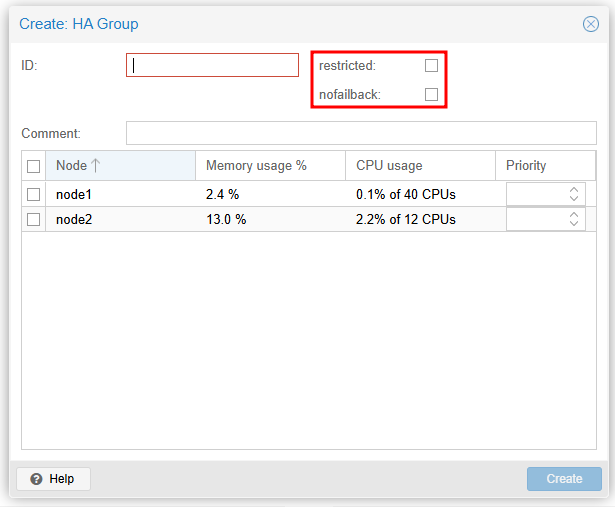
restricted:(기본값 = 0)
restricted 옵션을 활성화하면 제한된 그룹에 바인딩된 리소스는 그룹에서 정의한 노드에서만 실행되므로, 모든 그룹 노드 멤버가 온라인이 아니면 리소스는 중지된 상태가 됩니다. 제한 없는 그룹의 리소스는 모든 그룹 멤버가 오프라인인 경우 다른 모든 클러스터 노드에서 실행될 수 있지만 그룹 멤버가 온라인이 되면 다시 마이그레이션됩니다. 멤버가 하나만 있는 제한 없는 그룹을 사용하여 선호하는 노드 동작을 구현할 수 있습니다.
nofailback:(기본값 = 0)
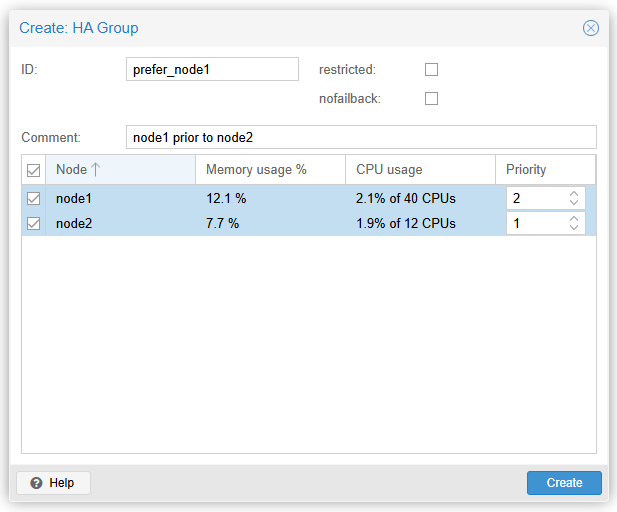
CRM(Cluster Resource Manager)은 가장 높은 우선순위를 가진 노드에서 서비스를 실행하려고 합니다. 우선순위가 더 높은 노드가 온라인이 되면 CRM은 해당 노드로 서비스를 마이그레이션합니다. nofailback 옵션을 활성화하면 이러한 동작이 방지됩니다.- node1에서 우선적으로 실행되어야 하는 VM(vm:101-win10)을 위한 HA Group입니다. node1의 우선순위가 높으며(2), node1이 장애로 인해 동작하지 않으면 node1에서 실행되던 VM들은 node2로 마이그레이션됩니다.
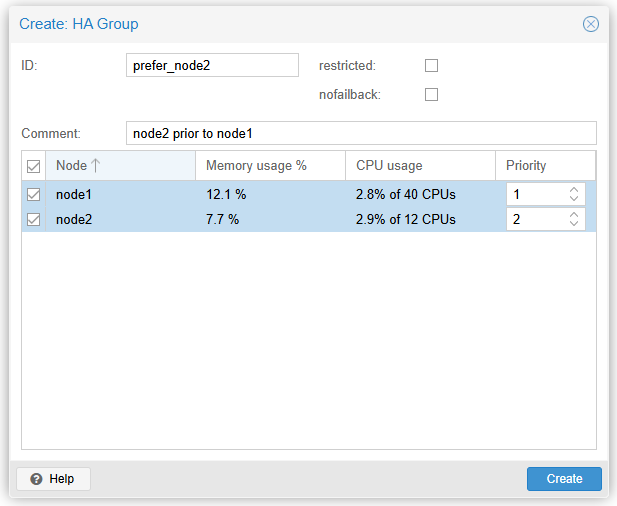
- node2에서 우선적으로 실행되어야 하는 VM(vm:100-kvmit)을 위한 HA Group입니다. node2의 우선순위가 높으며(2), node2가 장애로 인해 동작하지 않으면 node2에서 실행되던 VM들은 node1으로 마이그레이션됩니다.
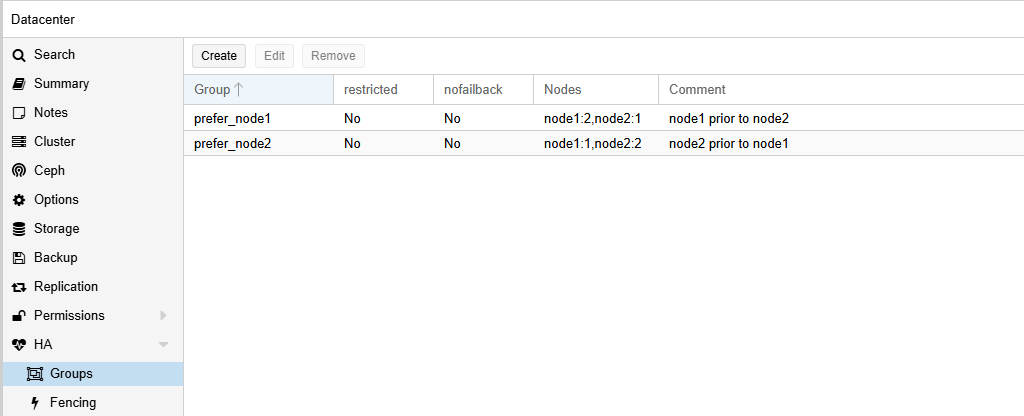
- 두 개의 HA Group이 생성된 것을 확인할 수 있습니다.
- node1에서 우선적으로 실행되어야 하는 VM(vm:101-win10)을 위한 HA Group입니다. node1의 우선순위가 높으며(2), node1이 장애로 인해 동작하지 않으면 node1에서 실행되던 VM들은 node2로 마이그레이션됩니다.
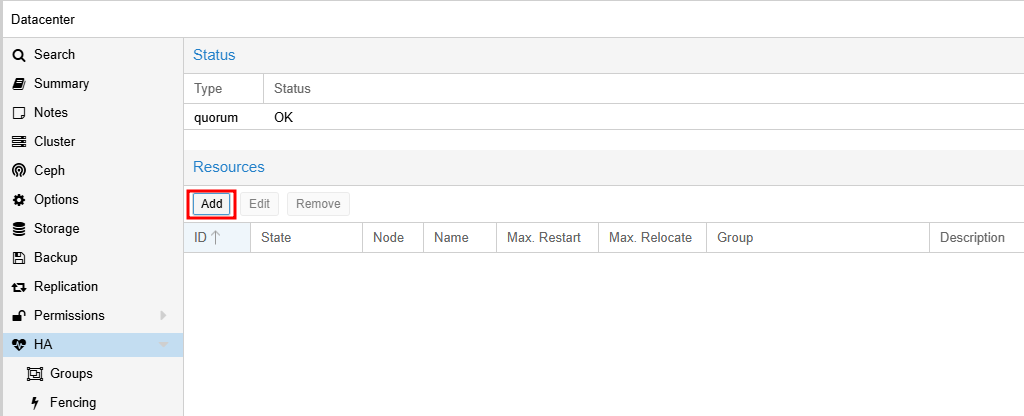
- Resource를 추가하기 위해
Datacenter > HA메뉴를 선택하고Add 버튼을 클릭합니다. 2개의 Resource(vm:100, vm:101)를 추가할 예정입니다.
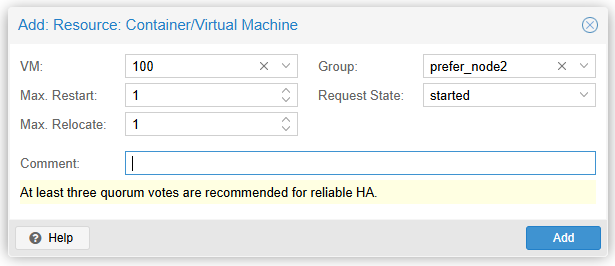
- vm:100을 추가하겠습니다. Group 옵션에
2 단계에서 생성한 HA Group(prefer_node2)을 선택합니다. vm:100은 node2에서 우선 실행되고, node2에 장애가 발생하면 node1으로 마이그레이션되며, node2가 복구되면 vm:100은 node2로 다시 마이그레이션됩니다.(node2 > node1 > node2)
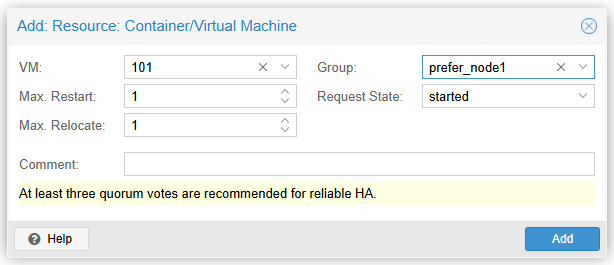
- vm:101을 추가하겠습니다. Group 옵션에
2 단계에서 생성한 HA Group(prefer_node1)을 선택합니다. vm:101은 node1에서 우선 실행되고, node1에 장애가 발생하면 node2로 마이그레이션되며, node1이 복구되면 vm:100은 node1으로 다시 마이그레이션됩니다.(node1 > node2 > node1)
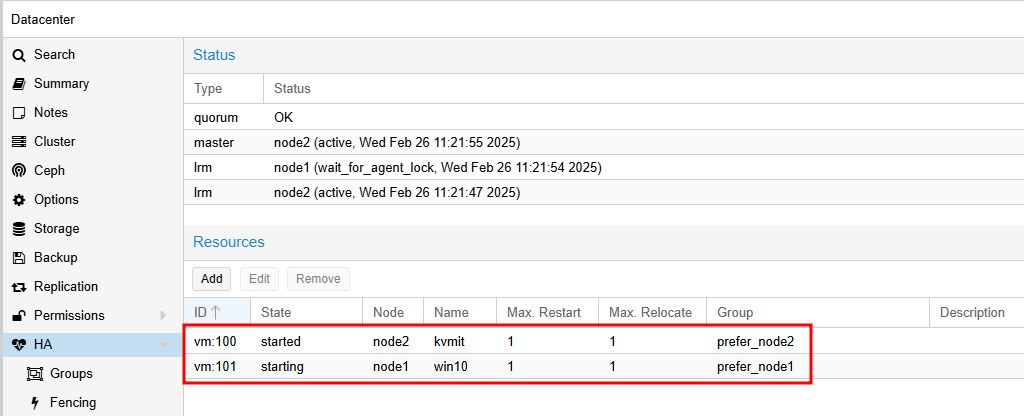
- 2개의 Resource(vm:100, vm:101)가 추가된 것을 확인할 수 있습니다.
- vm:100을 추가하겠습니다. Group 옵션에
- node2에 장애가 발생하는 상황을 만들어서, vm:100이 node1으로 마이그레이션되는지 테스트해보겠습니다.
- vm:100은 node2에서 정상적으로 실행되고 있습니다.
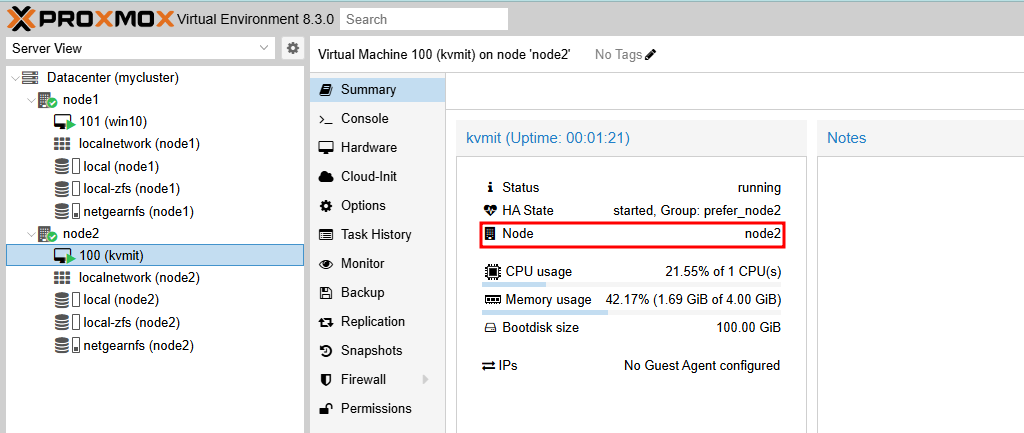
- node2에 장애가 발생하면 vm:100은 fencing상태가 되면서 node1으로 마이그레이션이 진행됩니다.
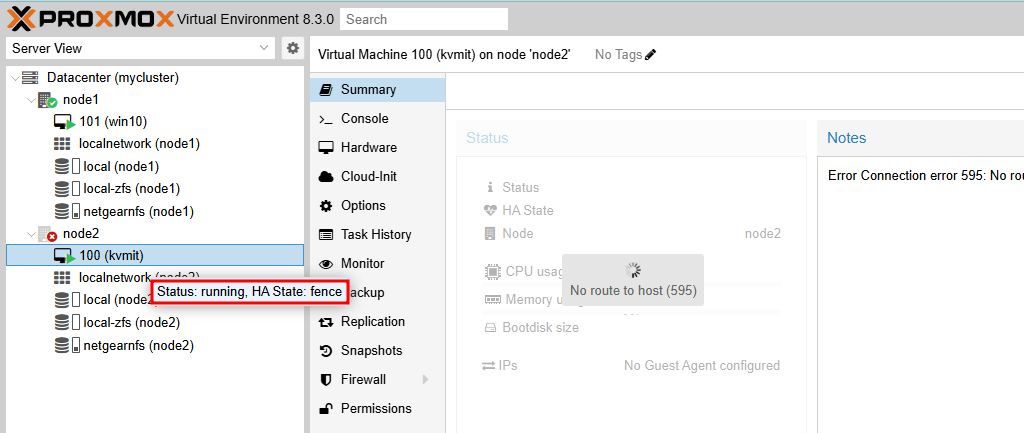
노드 장애 시 Fencing은 오류가 있는 노드가 오프라인 상태가 되도록 보장합니다. 이는 다른 노드에서 복구될 때 리소스가 두 번 실행되지 않도록 하는 데 필요합니다. 이는 정말 중요한 작업인데, 이것이 없다면 다른 노드에서 리소스를 복구할 수 없기 때문입니다. 장애 노드가 Fencing되지 않으면 공유 리소스에 여전히 액세스할 수 있는 알 수 없는 상태되어 정말 위험합니다. 스토리지 네트워크만 제외하고 모든 네트워크가 끊어졌다고 상상해 보세요. 이제 공용 네트워크에서 접근할 수 없지만 VM은 여전히 실행되고 공유 스토리지에 씁니다. 그런 다음 다른 노드에서 이 VM을 시작하면 두 노드에서 모두 쓰기 때문에 위험한 경쟁 조건이 발생합니다. 이러한 조건은 모든 VM 데이터를 파괴하고 전체 VM을 사용할 수 없게 만들 수 있습니다. 스토리지가 여러 마운트로부터 보호하는 경우에도 복구가 실패할 수 있습니다. - vm:100이 node1으로 마이그레이션되어 정상적으로 작동되는 것을 확인할 수 있습니다.
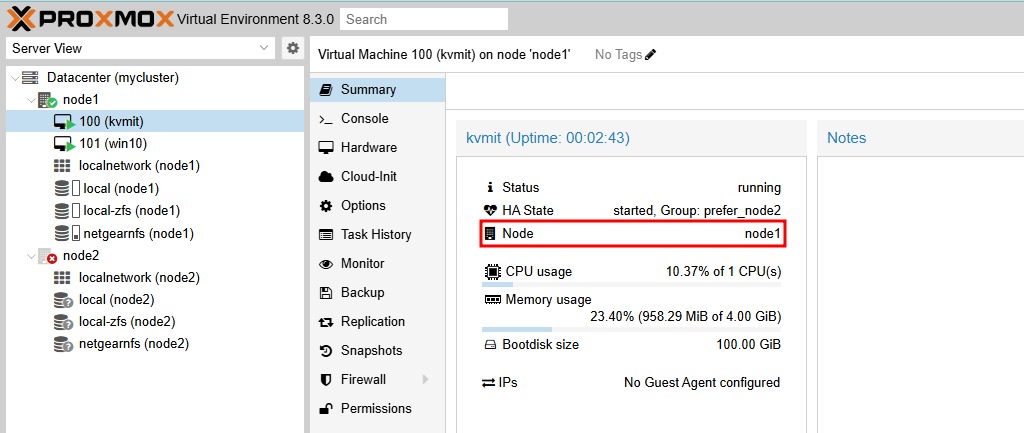
- node2가 정상적으로 복구되면 vm:100은 node2로 다시 마이그레이션됩니다.
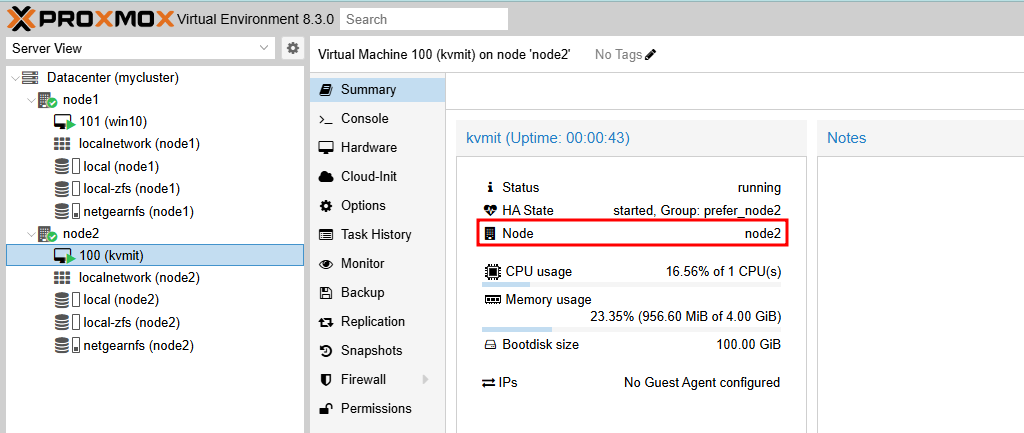
- vm:100은 node2에서 정상적으로 실행되고 있습니다.
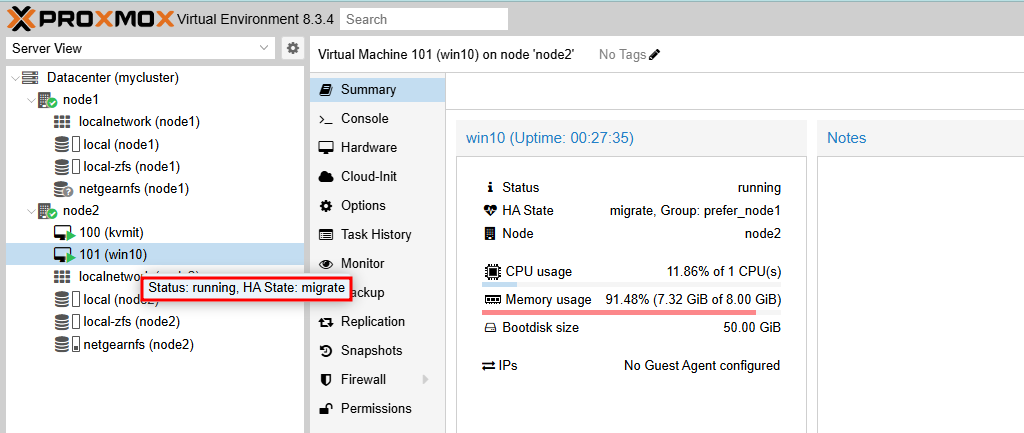
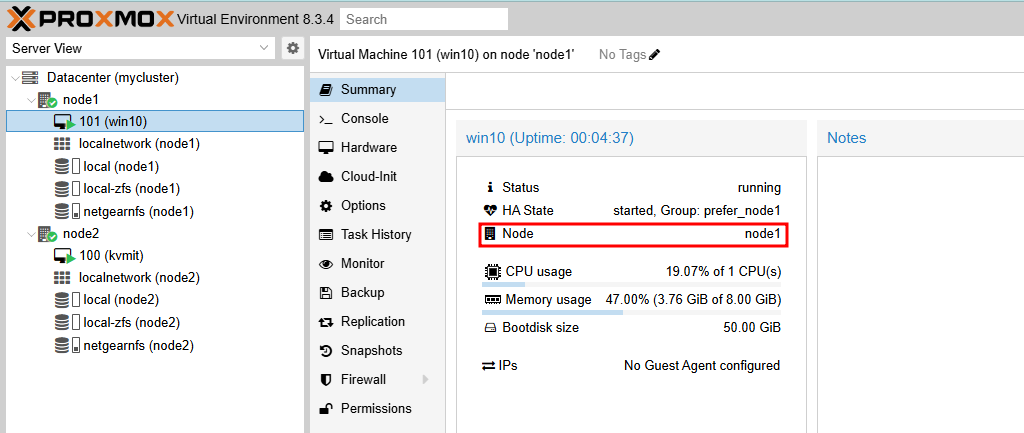
- 마찬가지로 node1에 장애가 발생하면, vm:101은 node2로 마이그레이션되고(HA State: migrate), node1이 복구되면 node1으로 다시 마이그레이션됩니다.