[Linux] SnmpTrap을 사용해서 WhatsUp Gold에서 서버 자원을 Passive Monitoring하는 방법
이 글에서는 SNMP를 사용해서 WhatsUp Gold에서 사용자 정의 MIB를 Active Monitoring하는 방법을 알아보았습니다. 오늘은 SnmpTrap을 사용해서 WhatsUp Gold에서 서버 자원을 Passive Monitoring하는 방법을 알아보겠습니다.
- SnmpTrap을 사용하기 위한 Shell Script 작성
- WhatsUp Gold에서 Snmp Trap Log 확인하기
- 주기적으로 Shell Script를 실행하는 방법(cron vs. systemd timer)
- WhatsUp Gold에서 Passive Monitoring을 위한 Actions and Policies 등록하기(slack 이용)
- Device Properties에 Passive Monitor 등록하기
- Slack 메세지 확인
1. SnmpTrap을 사용하기 위한 Shell Script 작성
- 메모리, CPU, 디스크의 사용량 임계치 등록: MEM_THRESHOLD, CPU_THRESHOLD, DISK_THRESHOLD
- 사용량을 모니터링한 디스크/파티션 등록(마운팅 포인트) : MONITOR_DISKS
- WhatsUp Gold에 SnmpTrap 메세지를 전송하기 위한 정보 등록 : NMS_IP, COMMUNITY, OID 등
$ vi snmptrap_msg.sh#!/bin/bash # set up the thresholds MEM_THRESHOLD=80 # Memory Usage Threshold(80%) CPU_THRESHOLD=70 # CPU Usage Threshold(70%) : 60seconds average DISK_THRESHOLD=80 # Disk Usage Threshold(90%) # Disk list for monitoring MONITOR_DISKS=("/" "/package") # Variable for Usage Message TMP_MSG="" # Variable for Warnings Message WARN_MSG="" # Caculating Memory Usage (/proc/meminfo) MemTotal=$(grep MemTotal /proc/meminfo | awk '{print $2}') MemAvailable=$(grep MemAvailable /proc/meminfo | awk '{print $2}') MemUsed=$((MemTotal - MemAvailable)) MemUsage=$((MemUsed * 100 / MemTotal)) TMP_MSG+="Memory Usage: $MemUsage%\n" if [ "$MemUsage" -gt "$MEM_THRESHOLD" ]; then WARN_MSG+="Memory usage exceeds $MEM_THRESHOLD%! Current: $MemUsage%\n" fi # Caculating CPU Usage (/proc/stat) : 60seconds average read cpu1 user1 nice1 system1 idle1 iowait1 irq1 softirq1 steal1 guest1 guest_nice1 < /proc/stat CPU_IDLE1=$((idle1 + iowait1)) CPU_NONIDLE1=$((user1 + nice1 + system1 + irq1 + softirq1 + steal1)) CPU_TOTAL1=$((CPU_IDLE1 + CPU_NONIDLE1)) #When testing, set 1 second sleep 60 read cpu2 user2 nice2 system2 idle2 iowait2 irq2 softirq2 steal2 guest2 guest_nice2 < /proc/stat CPU_IDLE2=$((idle2 + iowait2)) CPU_NONIDLE2=$((user2 + nice2 + system2 + irq2 + softirq2 + steal2)) CPU_TOTAL2=$((CPU_IDLE2 + CPU_NONIDLE2)) CPU_TOTAL_DELTA=$((CPU_TOTAL2 - CPU_TOTAL1)) CPU_IDLE_DELTA=$((CPU_IDLE2 - CPU_IDLE1)) CPU_USAGE=$(( (100 * (CPU_TOTAL_DELTA - CPU_IDLE_DELTA)) / CPU_TOTAL_DELTA )) TMP_MSG+="CPU Usage: $CPU_USAGE%\n" if [ "$CPU_USAGE" -gt "$CPU_THRESHOLD" ]; then WARN_MSG+="CPU usage exceeds $CPU_THRESHOLD%! Current: $CPU_USAGE%\n" fi # Caculating Disk Usage for DISK in "${MONITOR_DISKS[@]}"; do DiskUsage=$(df -h "$DISK" | awk 'NR==2 {gsub("%","",$5); print $5}') TMP_MSG+="Disk Usage on $DISK: $DiskUsage%\n" if [ "$DiskUsage" -gt "$DISK_THRESHOLD" ]; then WARN_MSG+="Disk usage on $DISK exceeds $DISK_THRESHOLD%! Current: $DiskUsage%\n" fi done # Printing Message # SNMP Trap Info # OID: snmptranslate -On NET-SNMP-EXTEND-MIB::nsExtendOutputFull.\"snmptrap_msg\" # .1.3.6.1.4.1.8072.1.3.2.3.1.2.<length>.<ASCII_of_each_char> NMS_IP="192.168.56.101" COMMUNITY="public" OID=".1.3.6.1.4.1.8072.1.3.2.3.1.2.12.115.110.109.112.116.114.97.112.95.109.115.103" UPTIME="0" if [ -n "$WARN_MSG" ]; then WARN_MSG="\n\n< Warnings about resources >\n${WARN_MSG}" echo -e "$WARN_MSG" snmptrap -v 2c -c $COMMUNITY $NMS_IP "" $UPTIME $OID s "$(echo -e ${WARN_MSG})" else TMP_MSG="\n\n< All system resources are within thresholds. >\n${TMP_MSG}" echo -e "$TMP_MSG" #Uncomment after testing snmptrap -v 2c -c $COMMUNITY $NMS_IP "" $UPTIME $OID s "$(echo -e ${TMP_MSG})" fi$ chmod +x snmptrap_msg.sh; ./snmptrap_msg.sh< All system resources are within thresholds. > Memory Usage: 13% CPU Usage: 3% Disk Usage on /: 44% Disk Usage on /package: 45%
2. WhatsUp Gold에서 Snmp Trap Log 확인하기
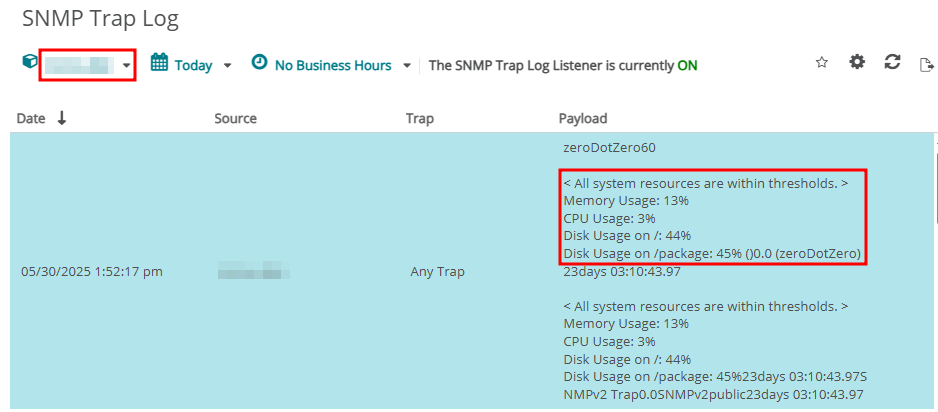
WhatsUp Gold > ANALYZE > Logs > SNMP Trap메뉴를 선택합니다.- 1단계에서 작성한 Shell Script를 실행합니다.
- Payload 메세지가 1단계에서 출력된 메세지가 동일한지 확인합니다.
3. 주기적으로 Shell Script를 실행하는 방법(cron vs. systemd timer)
- crontab을 사용하여 등록하기(최소 1분마다 실행)
$ crontab -e*/1 * * * * /path/to/snmptrap_msg.sh
- systemd의 Timer를 사용하기(초단위로 실행 주기 지정 가능)
현대 Linux에서 권장되는 주기적 작업 관리 방법으로 스크립트 + 로그 관리 + 서비스 연동까지 고려한다면 cron보다 systemd timer가 좋음.- 서비스 유닛 파일과 타이머 유닛 파일 작성
$ vi /etc/systemd/system/snmptrap_msg.service[Unit] Description=System Resource Monitoring Script [Service] Type=oneshot ExecStart=/path/to/snmptrap_msg.sh$ vi /etc/systemd/system/snmptrap_msg.timer[Unit] Description=Run System Resource Monitoring Every 10 Seconds [Timer] OnBootSec=10sec # 부팅 후 10초 뒤 첫 실행 #When testing, set 10sec OnUnitActiveSec=70sec # 이후 70초마다 반복, 60초보다 커야합니다. Persistent=true # 부팅 중 missed 타이머 catch-up [Install] WantedBy=timers.target
- systemctl 명령으로 활성화 및 시작
$ systemctl daemon-reload $ systemctl enable --now snmptrap_msg.timer
systemctl명령어와journalctl명령어로 타이머 유닛이 정상적으로 동작했는지 확인해 봅니다.$ systemctl status snmptrap_msg.timer* snmptrap_msg.timer - Run System Resource Monitoring Every 10 Seconds Loaded: loaded (/etc/systemd/system/snmptrap_msg.timer; disabled; vendor preset: disabled) Active: active (elapsed) since 025-05-30 14:55:11 KST; 2s ago 50 14:55:11 non-w-dev systemd[1]: Started Run System Resource Monitoring Every 10 Seconds.$ journalctl -u snmptrap_msg.timer-- Logs begin at 025-05-07 10:41:34 KST, end at 025-05-30 14:50:30 KST. -- 50 14:50:18 non-w-dev systemd[1]: Started Run System Resource Monitoring Every 10 Seconds.WhatsUp Gold > ANALYZE > Logs > SNMP Trap에서 약 10초마다 한 번씩 메세지가 출력되는지 확인합니다.
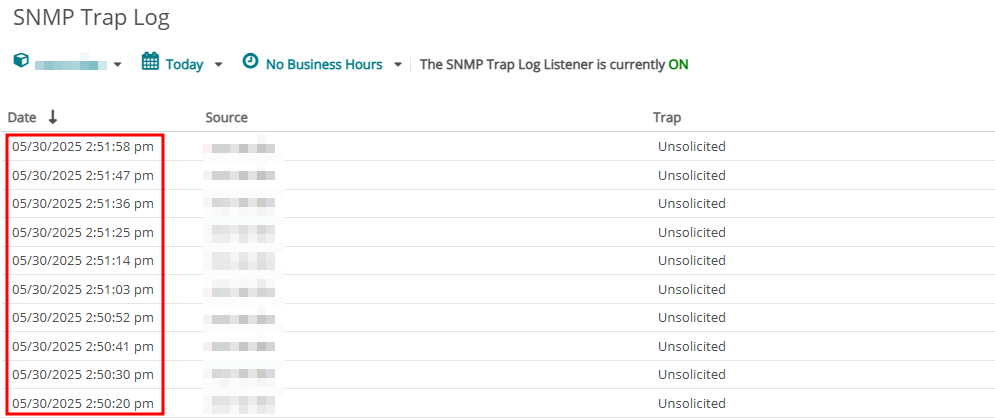
- WhatsUp Gold에서 정상적으로 SNMP Trap Log가 표시되면
systemctl stop snmptrap_msg.timer명령으로 타이머 유닛을 일단 중지시킵니다.
- 서비스 유닛 파일과 타이머 유닛 파일 작성
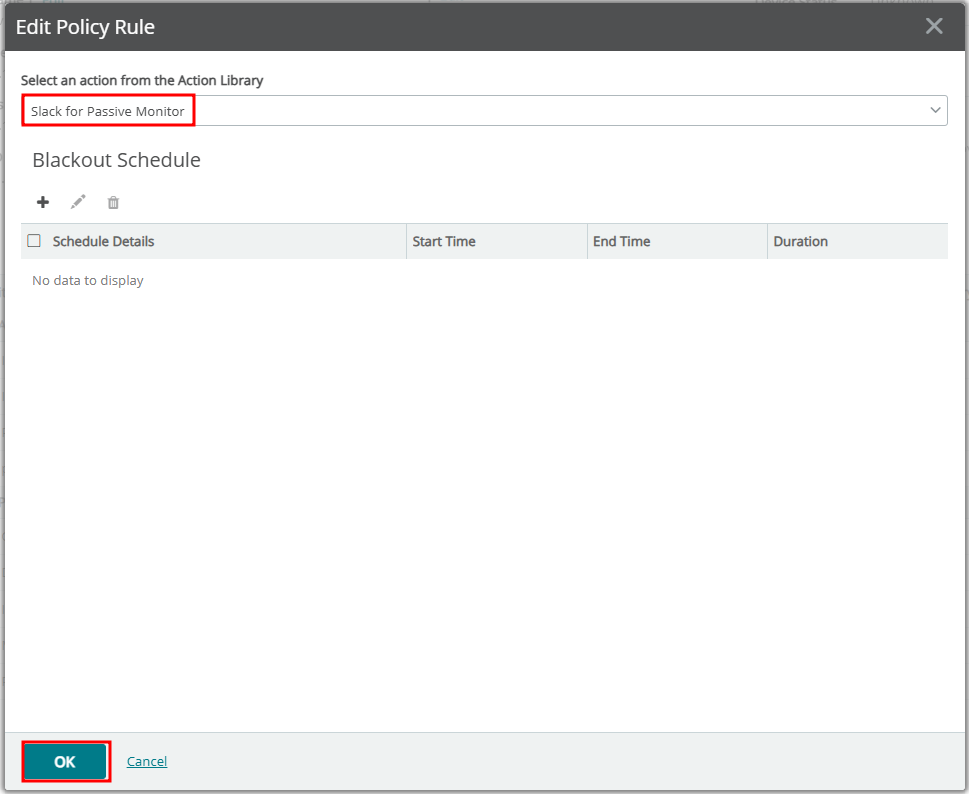
4. WhatsUp Gold에서 Passive Monitoring을 위한 Actions and Policies 등록하기(slack 이용)
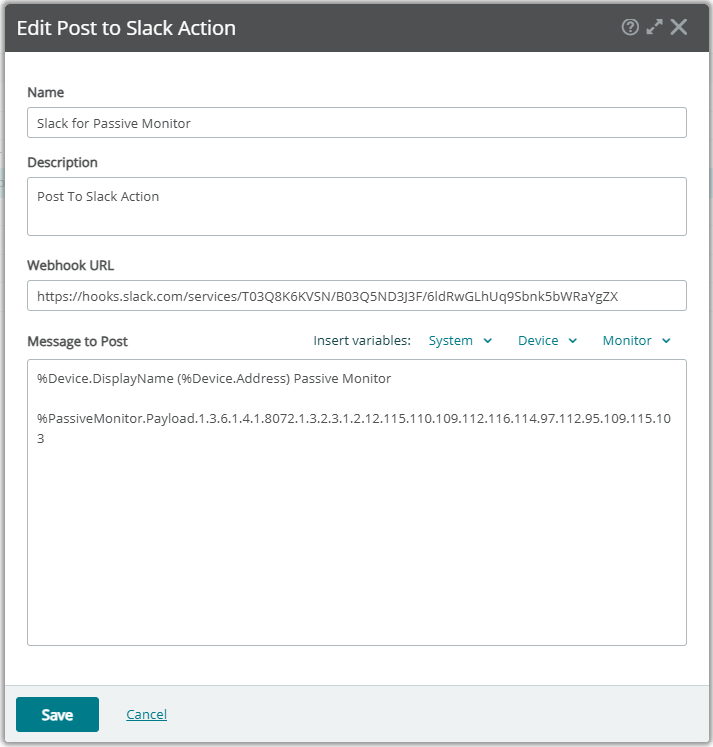
- SETTING > Actions and Alerts > Actions and Policies 메뉴로 이동합니다.
- Post to Slack Action을 아래와 같이 설젇합니다. WhatsUp Gold 메뉴얼을 참고하시기 바랍니다.
5. Device Properties에 Passive Monitor 등록하기
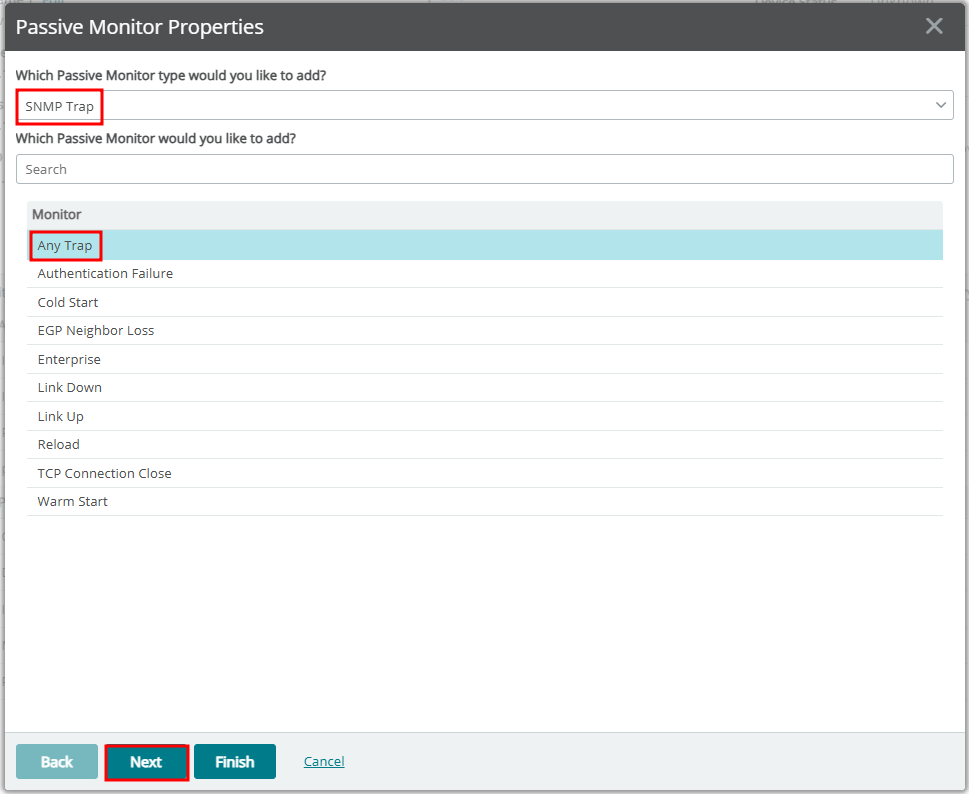
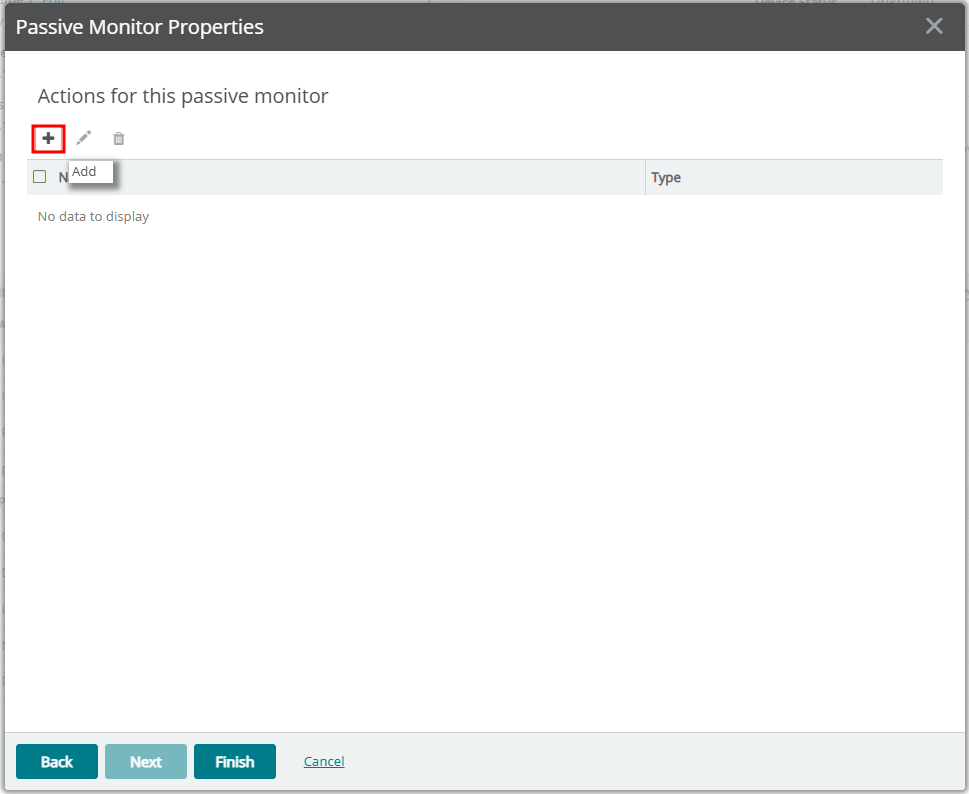
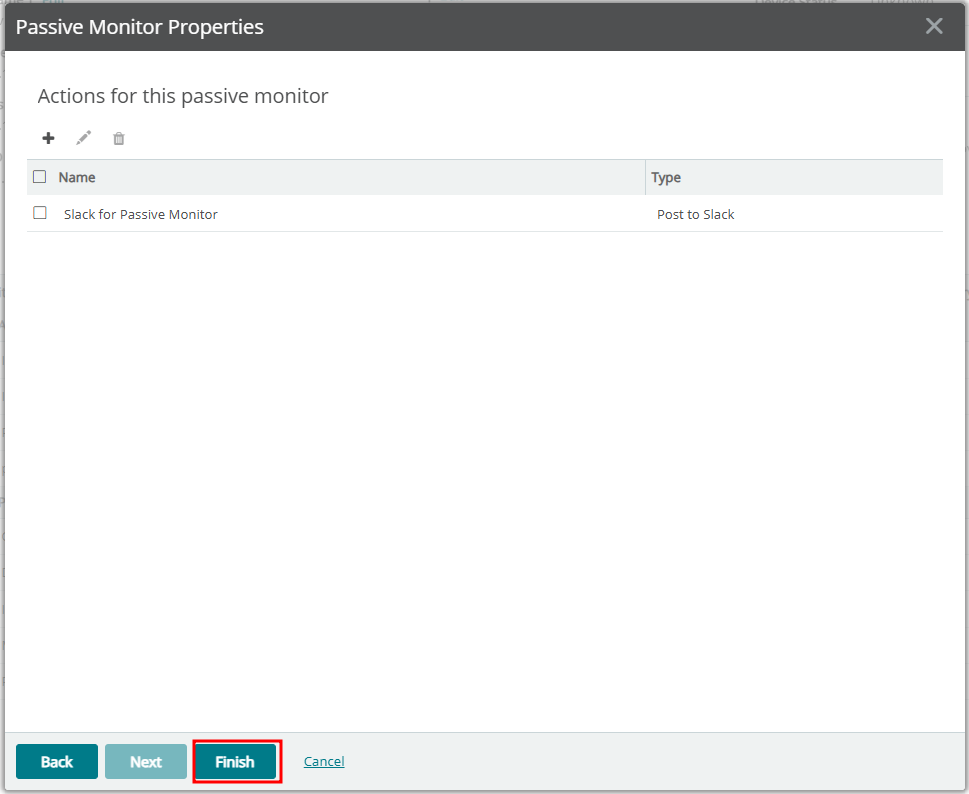
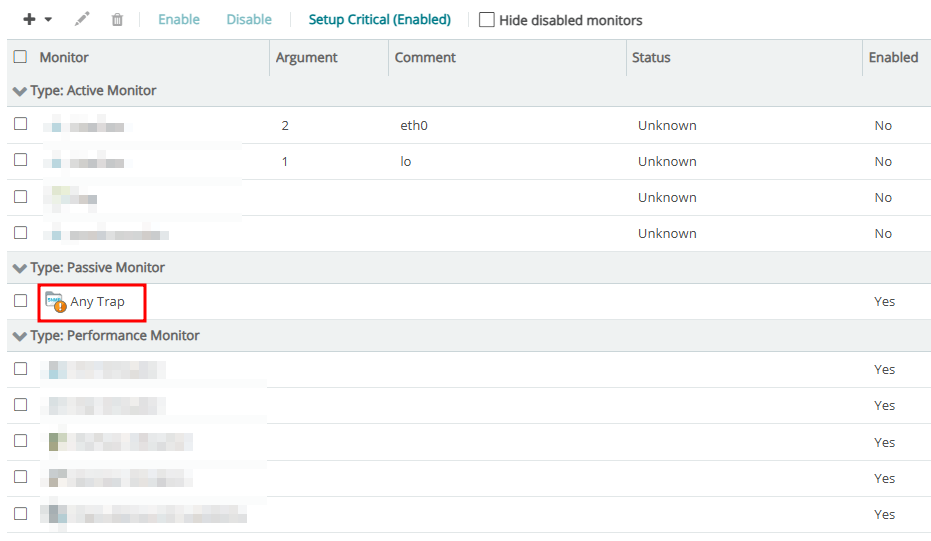
6. Slack 메세지 확인
systemctl start snmptrap_msg.timer; systemctl start snmptrap_msg.service명령으로 타이머 유닛과 서비스 유닛을 다시 시작시킵니다.- Slack 채널에 메시지가 약 10초마다 한 번씩 전송되는지 확인합니다.

- 정상적으로 메세지가 출력되면 1단계에서 작성한 snmptrap_msg.sh 파일의 붉은색 부분을 Uncomment합니다.
- 임계치를 아래와 같이 수정한 후 Warning 메세지가 정상적으로 전송되는지 확인해 봅니다. 정상 작동이 확인되면 임계치를 원복시킵니다.
# set up the thresholds MEM_THRESHOLD=1 # memory Usage Threshold(80%) CPU_THRESHOLD=1 # CPU Usage Threshold(70%) : 60seconds average DISK_THRESHOLD=1 # Disk Usage Threshold(80%)