
[Oracle] 분석함수와 OVER( ) 문 사용법
| 카테고리 | 분석 함수 |
|---|---|
| 집계 | COUNT( ), MAX( ), MIN( ), SUM( ), AVG( ) |
| 순위 | ROW_NUMBER( ): 결과 집합 내에서 각 행에 순차적인 일련번호(고유한 번호)를 할당하며 중복된 값이 있어도 고유한 번호가 할당됩니다 RANK( ): 정렬된 결과 집합에서 각 행의 순위를 할당하며 동일한 값이 있을 경우에는 동일한 순위가 할당되며, 그 다음 순위는 건너뛰고 다음 순위가 할당됩니다 DENSE_RANK( ): RANK와 유사하지만, 동일한 값이 있을 경우에도 순위를 중복 없이 순차적으로 할당하며 순위가 건너뛰지 않고 연속적으로 할당됩니다 |
| 순서 | FIRST_VALUE( ): 각 그룹 내에서 가장 먼저 발생하는 값이나 정렬된 결과 집합에서 첫 번째 값 등을 가져옵니다 LAST_VALUE( ): 그룹 내에서 가장 마지막으로 발생하는 값을 가져오거나, 정렬된 결과 집합에서 마지막 값 등을 가져옵니다 LAG( ): 이전 행의 값을 가져와서 현재 행과 비교하는 데 사용됩니다. LEAD( ): 현재 행 다음의 값을 가져와서 현재 행과 비교하는 데 사용됩니다. |
| 통계 | STDDEV( ), VARIANCE( ), MEDIAN( ) |
| 비율 | <Windowing Clause에서 사용 가능> RATIO_TO_REPORT(컬럼): 0에서 1 사이의 실수값으로, 각 행의 값이 전체 값 중에서 차지하는 비율을 계산합니다. CUME_DIST( ): 0에서 1 사이의 실수값으로, 현재 행이 속한 그룹 내에서 현재 행보다 작거나 같은 값을 가진 행들의 누적 비율을 계산합니다. PERCENT_RANK( ): 0에서 1 사이의 실수값으로, 현재 행이 속한 그룹 내에서 현재 행보다 작은 값을 가진 행들의 누적 비율을 계산합니다. NTILE(숫자): 1부터 n까지의 값을 가지며, 결과 집합을 동일한 크기의 버킷 또는 그룹으로 나누고 각 행을 해당 버킷에 할당합니다. |
| 백분위 | <ORDER BY 절을 기반으로 하여 백분위수를 계산> PERCENTILE_DISC( ): 이산형(discrete) 백분위수를 계산하며, 순위를 기반으로 하여 결과 집합 내에 존재하는 실제 값 중 가장 가까운 순위에 있는 값을 반환합니다. PERCENTILE_CONT( ): 연속형(continuous) 백분위수를 계산하며, 선형 보간(linear interpolation)을 사용하여 결과 집합 내에서 값들 사이의 추정된 값을 반환합니다. |
위 함수들은 SQL문서에서 자주 볼 수 있는 분석함수들입니다. 아래 데이터로 OVER() 문과 함께 분석함수들의 사용법을 알아보겠습니다. OVER() 를 사용하면 GROUP BY나 서브 쿼리를 사용하지 않고 분석함수들을 사용할 수 있습니다.
WITH EMPLOYEE_TAB AS (
SELECT 1 AS EMPLOYEE_ID, 'John Doe' AS EMPLOYEE_NAME, 'IT' AS DEPARTMENT,
TO_DATE('2022-01-01', 'YYYY-MM-DD') AS HIRE_DATE, 'Developer' AS JOB, 60000 AS SALARY FROM DUAL UNION ALL
SELECT 2, 'Jane Smith', 'HR', TO_DATE('2022-02-15', 'YYYY-MM-DD'), 'Manager', 80000 FROM DUAL UNION ALL
SELECT 3, 'Michael Johnson', 'Finance', TO_DATE('2022-03-20', 'YYYY-MM-DD'), 'Accountant', 70000 FROM DUAL UNION ALL
SELECT 4, 'Emily Brown', 'Marketing', TO_DATE('2022-04-10', 'YYYY-MM-DD'), 'Analyst', 65000 FROM DUAL UNION ALL
SELECT 5, 'David Lee', 'IT', TO_DATE('2022-05-05', 'YYYY-MM-DD'), 'Programmer', 55000 FROM DUAL UNION ALL
SELECT 6, 'Sarah Wilson', 'Sales', TO_DATE('2022-06-18', 'YYYY-MM-DD'), 'Salesperson', 60000 FROM DUAL UNION ALL
SELECT 7, 'James Taylor', 'IT', TO_DATE('2022-07-22', 'YYYY-MM-DD'), 'Developer', 62000 FROM DUAL UNION ALL
SELECT 8, 'Linda Martinez', 'Finance', TO_DATE('2022-08-30', 'YYYY-MM-DD'), 'Accountant', 72000 FROM DUAL UNION ALL
SELECT 9, 'William Anderson', 'HR', TO_DATE('2022-09-12', 'YYYY-MM-DD'), 'Manager', 85000 FROM DUAL UNION ALL
SELECT 10, 'Jennifer Garcia', 'Marketing', TO_DATE('2022-10-05', 'YYYY-MM-DD'), 'Analyst', 67000 FROM DUAL
)
SELECT * FROM EMPLOYEE_TAB ;
EMPLOYEE_ID | EMPLOYEE_NAME | DEPARTMENT | HIRE_DATE | JOB | SALARY
------------|------------------|------------|------------|--------------|--------
1 | John Doe | IT | 2022-01-01 | Developer | 60000
2 | Jane Smith | HR | 2022-02-15 | Manager | 80000
3 | Michael Johnson | Finance | 2022-03-20 | Accountant | 70000
4 | Emily Brown | Marketing | 2022-04-10 | Analyst | 65000
5 | David Lee | IT | 2022-05-05 | Programmer | 55000
6 | Sarah Wilson | Sales | 2022-06-18 | Salesperson | 60000
7 | James Taylor | IT | 2022-07-22 | Developer | 62000
8 | Linda Martinez | Finance | 2022-08-30 | Accountant | 72000
9 | William Anderson | HR | 2022-09-12 | Manager | 85000
10 | Jennifer Garcia | Marketing | 2022-10-05 | Analyst | 67000
OVER() 문을 사용하는 방법을 먼저 알아보겠습니다.
분석함수( ) OVER(PARTITION BY 컬럼 / ORDER BY 컬럼 / Windowing Clause)
| 상세 설명 | |
|---|---|
| PARTITION BY 컬럼 | 어느 컬럼을 기준으로 쪼갤지를 의미한다. GROUP BY와 동일한 기능이라고 보면 되며 PARTITION BY JOB로 했을 시 JOB를 기준으로 쪼개개 된다 |
| ORDER BY 컬럼 | 정렬 시 기준을 설정해주며 기본은 오름차순이고 내림차순으로 설정해주려면 ORDER BY 컬럼 DESC를 써주면 된다 |
| Windowing Clause | 세부 분할 기준이라고 하는데 PARTITION BY, ORDER BY로 충분히 분할하지 못했을 경우 사용하며 ORDER BY를 사용한 상태에서만 적용 가능하다 조건에 맞는 ROW를 가지고 정렬: ROWS BETWEEN start_point AND end_point 조건에 맞는 값을 가지고 정렬: RANGE BETWEEN start_point AND end_point start_point에는 UNBOUNDED PRECEDING – 첫줄부터 CURRENT ROW – 현재 줄까지 값 PRECEDING – 값부터 end_point에는 |
집계 함수 사용법 및 결과
SELECT EMPLOYEE_ID, EMPLOYEE_NAME, DEPARTMENT, SALARY
, COUNT(*) OVER(PARTITION BY DEPARTMENT) AS COUNT1
, COUNT(*) OVER(PARTITION BY DEPARTMENT ORDER BY EMPLOYEE_ID) AS COUNT2
, SUM(SALARY) OVER(PARTITION BY DEPARTMENT) AS SUM1
, SUM(SALARY) OVER(PARTITION BY DEPARTMENT ORDER BY EMPLOYEE_ID) AS SUM2
FROM EMPLOYEE_TAB ;
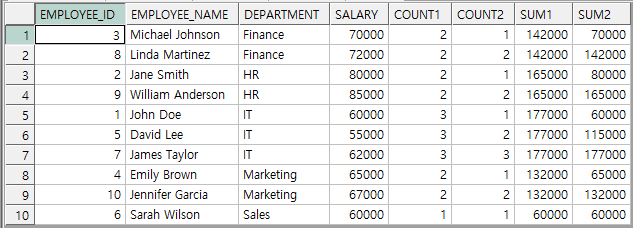
순위 함수 사용법 및 결과
RANK( )와 DENSE_RANK( ) 함수는 ORDER BY 필수
SELECT EMPLOYEE_ID, EMPLOYEE_NAME, DEPARTMENT, SALARY
, ROW_NUMBER() OVER(ORDER BY SALARY) AS ORDER1
, RANK() OVER(ORDER BY SALARY) AS ORDER2
, DENSE_RANK() OVER(ORDER BY SALARY) AS ORDER3
FROM EMPLOYEE_TAB ;
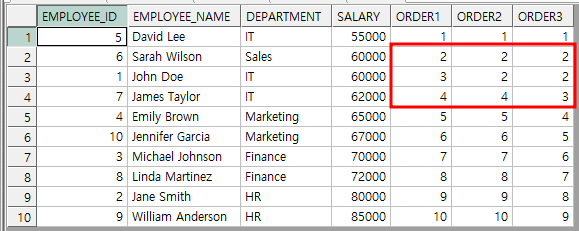
순서 함수 사용법 및 결과
SELECT EMPLOYEE_ID, EMPLOYEE_NAME, DEPARTMENT, SALARY
, FIRST_VALUE(SALARY) OVER(PARTITION BY DEPARTMENT ORDER BY SALARY) AS FIRST_V
, LAST_VALUE(SALARY) OVER(PARTITION BY DEPARTMENT ORDER BY SALARY) AS LAST_V
, LAG(SALARY) OVER(PARTITION BY DEPARTMENT ORDER BY SALARY) AS LAG_V
, LEAD(SALARY) OVER(PARTITION BY DEPARTMENT ORDER BY SALARY) AS LEAD_V
FROM EMPLOYEE_TAB ;
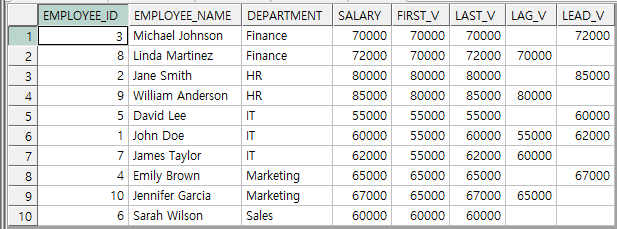
비율 함수 사용법 및 결과
CUME_DIST( ), PERCENT_RANK( )와 NTILE( ) 함수는 ORDER BY 필수
SELECT EMPLOYEE_ID, EMPLOYEE_NAME, DEPARTMENT, SALARY
, ROUND(RATIO_TO_REPORT(SALARY) OVER(), 2) AS RATIO_TO_REPORT
, CUME_DIST() OVER(ORDER BY SALARY) AS CUME_DIST
, ROUND(PERCENT_RANK() OVER(ORDER BY SALARY), 2) AS PERCENT_RANK
, NTILE(4) OVER(ORDER BY SALARY) AS NTILE
FROM EMPLOYEE_TAB ;
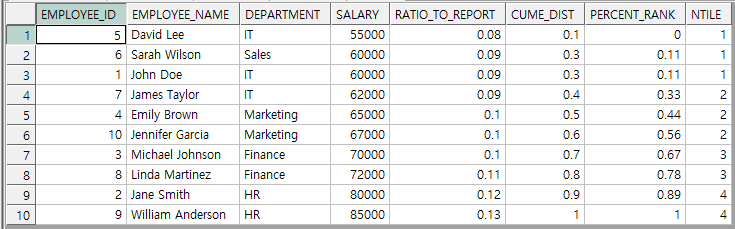
백분위 함수 사용법 및 결과
PERCENTILE_DISC( ) 함수와 PERCENTILE_CONT( ) 함수는 OVER ( ) 대신에 WITHIN GROUP ( )를 사용합니다.
SELECT PERCENTILE_DISC(0.25) WITHIN GROUP (ORDER BY SALARY) AS "DISC_Quartile1"
, PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY SALARY) AS "CONT_Quartile2"
, PERCENTILE_DISC(0.75) WITHIN GROUP (ORDER BY SALARY) AS "DISC_Quartile3"
, PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY SALARY) AS "CONT_Quartile1"
, PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY SALARY) AS "CONT_Quartile2"
, PERCENTILE_CONT(0.75) WITHIN GROUP (ORDER BY SALARY) AS "CONT_Quartile3"
FROM EMPLOYEE_TAB ;



